
Home
Welcome, my name is Markus Schneider. I am a computer scientist and researcher – developing machine learning, data science and deep-learning applications.
I attained my Ph.D. from the University of Ulm on “Expected Similarity Estimation for Large-Scale Anomaly Detection” [thesis] (see below). Previously I acquired a Master’s degree in Computer Science from the Ravensburg-Weingarten University and a Master by Research (M.Phil) in Machine Learning from the University of Sydney. In between I worked as a software engineer at Bosch Software Innovations.
Expected Similarity Estimation for Large-Scale Anomaly Detection
Anomalies are patterns in data or events which are unlikely to appear under normal conditions. It is of central interest to detect such anomalous instances to prevent damage or to extract valuable information from data. While statistics and machine learning developed several excellent key techniques to perform anomaly detection, most of them suffer poor algorithmic scalability when applied to large-scale datasets since the computational complexity and memory requirements become the limiting factor of these algorithms.
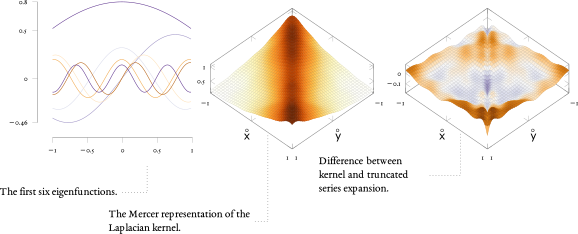
This dissertation makes several contributions to the problem of large-scale anomaly detection centered on a novel method we introduce named EXPoSE which estimates the similarity between a new unseen observation and the distribution data under normal conditions. That way EXPoSE measures the likelihood for a new observation to be anomalous. Its core is based on the kernel embedding of distributions which maps a probability measure into a reproducing kernel Hilbert space where it can be manipulated efficiently. The kernel embedding representation requires no parametric assumptions or explicit description of the probability measure. This constitutes an important advantage since the distributions of normal and anomalous instances are in general unknown.
The main contributions of this workare efficient algorithms to train and evaluate the EXPoSE anomaly detector. This can be achieved with computational complexities and memory requirements independent of the dataset size which is the key to solve large-scale machine learning problems. The dependence on the reproducing kernel function as a similarity measure enables the application to many domains and introduces the possibility to incorporate domain and expert knowledge into the modeling process.
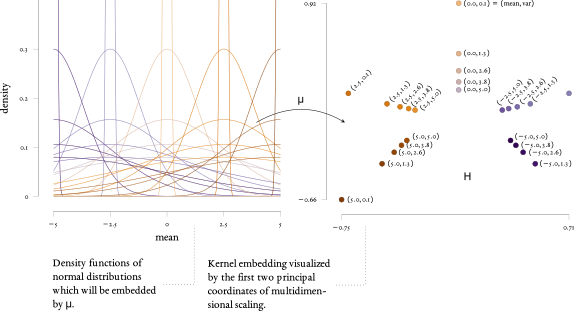
The key technologies are further developed to online and streaming anomaly detection where instances arrive in a possible infinite sequence of observations. A crucial requirement in these applications is the ability to make predictions as data arrive based on the information obtained from previous observations. One of the major challenges is the non-stationary nature of streams in which our understanding of what is normal and anomalous change over time. This introduces the necessity to adapt to such changes e.g. by forgetting outdated information while incorporating new knowledge.
The simplicity of the proposed methodologies facilitates a theoretical analysis to provide guarantees in terms of convergence rates and probabilistic bounds.
Publications
This is a list of my recent featured publictions
2017
Schneider, Markus
Expected Similarity Estimation for Large-Scale Anomaly Detection.
Open Access Repositorium der Universität Ulm. PhD Dissertation (2017). doi:10.18725/OPARU-4222
2016
Schneider, M.
Probability Inequalities for Kernel Embeddings in Sampling without Replacement.
in Proceedings of the 19th International Conference on Artificial Intelligence and Statistics (AISTATS 2016) 66–74 (2016).
[pdf]
Schneider, M., Ertel, W. & Ramos, F.
Kernel Embeddings for Large-Scale Anomaly Detection.
in International Conference on Machine Learning (ICML 2016): Anomaly Detection Workshop (2016).
Schneider, M., Ertel, W. & Ramos, F.
Expected Similarity Estimation for Large-Scale Batch and Streaming Anomaly Detection.
Machine Learning Journal 105, 305–333 (2016).
doi:10.1007/s10994-016-5567-7
[preprint]
Schneider, M., Ertel, W. & Palm, G.
Constant Time EXPected Similarity Estimation for Large-Scale Anomaly Detection.
in Proceedings of the 22nd European Conference on Artificial Intelligence (ECAI 2016) 12–20 (IOS Press, 2016).
doi:10.3233/978-1-61499-672-9-12
[preprint]
2015
Schneider, M., Ertel, W. & Palm, G.
Kernel Feature Maps from Arbitrary Distance Metrics.
in KI 2015: Advances in Artificial Intelligence (eds. Hölldobler, S., Krötzsch, M., Peñaloza, R. & Rudolph, S.) 137–150 (Springer International Publishing, 2015). doi:10.1007/978-3-319-24489-1_11
Schneider, M., Ertel, W. & Palm, G.
Expected Similarity Estimation for Large-Scale Anomaly Detection.
in Proceedings of the International Joint Conference on Neural Networks (IJCNN 2015) 1–8 (IEEE, 2015).
doi:10.1109/ijcnn.2015.7280331
Older
Schneider, M. & Ramos, F.
Transductive Learning for Multi-Task Copula Processes. in European Conference on Artificial Intelligence (ECAI 2014) 1089–1090 (IOS Press, 2014). doi:10.3233/978-1-61499-419-0-1089
Schneider, M. & Ertel, W.
Robot Learning by Demonstration with local Gaussian process regression. in Intelligent Robots and Systems (IROS 2010), 255–260 (2010). doi:10.1109/IROS.2010.5650949